
Après une première partie dévolue aux basiques de l’intelligence artificielle, une seconde à ses principales briques technologiques et une troisième à l’étude de cas d’IBM Watson et à un aperçu des méthodes marketing des startups du secteur, nous voici dans la quatrième partie de cette série dédiée à l’intelligence artificielle consacrée à quelques startups du secteur.
Je vais essayer de segmenter ce marché, d’en identifier les tendances et lignes de force, de voir comment il se structure (verticalement, horizontalement) et comment il s’organise entre produits, données et services. Je vais aussi essayer d’identifier ce qui est rare dans ce marché.
Certains spécialistes de l’IA m’ont à juste titre fait remarquer dans les commentaires aux précédents articles que l’IA en était encore au stade artisanal et principalement de l’ordre du bricolage. Cela ne se voit évidemment pas directement quand on fait le tour d’horizon des startups du secteur. Surtout dans le mesure où la plupart d’entre elles sont “b-to-b” et diffusent leurs solution en marque blanche. Vous les retrouverez éventuellement dans les agents conversationnels des sites web de marques, dans le ciblage marketing qui vous touche avec une offre pertinente (ou pas du tout…), dans des robots capables de dialoguer plus ou moins avec vous, ou dans les aides à la conduite dans votre voiture haut de gamme semi-automatique.
L’un des moyens de se rendre compte indirectement de cet aspect artisanal consiste à d’évaluer la part produit et la part service des entreprises du secteur. Plus la part du produit est faible, plus on est dans le domaine de l’artisanal. Cela n’apparait pas dans les données publiques mais peut au moins d’obtenir quand on a l’occasion d’observer à la loupe ces entreprises : dans le cadre d’une relation grand compte/startup, d’un investissement ou même d’un recrutement. On peut l’observer également dans les profils LinkedIn des salariés de l’entreprise s’ils sont disponibles. Bref en utilisant ce que l’on appelle des sources d’information “ouvertes”.
Cartographies des startups de l’intelligence artificielle
Pour cette partie, je vais m’appuyer sans vergogne sur ce suivi du secteur par le site VentureScanner qui était actualisé en mars 2016. Il organise le marché des startups de l’intelligence artificielle en 13 segments et évalue leur ancienneté et leur financement.

Au vu de ce grand schéma, j’organiserai cela avec pour commencer les segments du Machine Learning et du Deep Learning sont les plus représentés avec 123 startups identifiées pour les outils génériques et 260 pour des applications métier. On trouve 684 startups utilisant du machine learning dans la Crunchbase.
Ensuite, les agents conversationnels sont dans 92 startups, les agents intelligents qui comprennent leur environnement et agissent en conséquence sont 28. Suivent la robotique avec 65 startups, la traduction automatique avec 15 startups et les moteurs de recommandation qui représentent 66 startups.
Enfin, les startups gérant les solutions de perception : le traitement du langage avec 232 startups, la vision artificielle avec 189 startups, la reconnaissance de vidéos avec 14 startups et le contrôle gestuel avec 33 startups.
On constate une évolution à la hausse du financement des startups de ces secteurs. De 2009 à 2015, c’est une évolution constante, avec une courbe en cloche atteignant visiblement son pic en 2015. Mais cette évolution a marqué de très nombreux secteurs d’activité comme les Fintechs, le retail, ou le e-commerce. L’IA n’est pas encore une priorité nette des VCs qui mettent encore le paquet sur des secteurs traditionnels. Nous avons ici $1,2B d’investissements dans l’IA pour $59B en 2015, en tout rien qu’aux USA !

L’ancienneté des startups de ce secteur est plutôt grande avec un bel étalement sur la date de création. Il y a certes un pic entre 2010 et 2012 mais un gros volume de startups créées entre 2006 et 2010. Elles sont encore là car elles doivent probablement cibler des marchés d’entreprises. Les investisseurs ont tendance à financer des startups plutôt matures dans ce secteur. Les startups les plus anciennes de l’IA sont celles de la reconnaissance de la parole et de la vidéo, qui ont respectivement 8 et 6,5 ans d’ancienneté.

Ces startups ont généralement quelques points communs marquants :
- Elles ont quasiment toutes des approches marché “b-to-b” avec des marchés visés qui sont toujours les mêmes, entre horizontal et vertical. Exemples de marché sursaturés : la détection de fraudes dans la finance et et l’analyse prédictive du comportement des consommateurs.
- On y trouve régulièrement les ombres de la DARPA, de la NSA et de la CIA comme clients voire même comme investisseurs pour cette dernière ! Surtout pour les solutions “horizontales”. Ce n’est pas une question de “Small Business Act” mais simplement de besoins de ces organisations de défense et de renseignement !
- Les technologies d’IA employées sont assez mal documentées. Le machine learning et le deep learning reviennent souvent sans que l’on puisse évaluer si les startups ont réellement fait avancer l’état de l’art. Comme il se doit, une startup doit présenter un risque marché plus qu’un risque technologique ou scientifique. C’est pourquoi les startups de l’IA sont généralement positionnées dans l’application de techniques d’IA connues à des marchés divers, horizontaux ou verticaux. Elles profitent aussi parfois de l’effet d’opportunité en labellisant “IA” des projets qui quelques années auparavant auraient été vendus sous le sceau du “big data”.
- Les solutions sont très souvent proposées sous la forme d’APIs en cloud mais les approches plateformes sont encore en devenir et balbutiantes car elles ne bénéficient pas d’un effet push/pull courant dans le grand public (la demande pour des smartphones Android entraînant celles d’applications tournant dessus).
- Les levées de fonds sont encore relativement modestes dans l’ensemble. On dépasse dans de rares cas les $100m. Ce n’est pas beaucoup par rapport à plus de $1B réalisées par des licornes telles que Pinterest, où l’intensité technologique est plus faible. Les licornes sont presque toutes des startups grand public.
- Le secteur donne lieu à de nombreuses acquisitions mais Google n’a pas acquis tout ce qui était intéressant ! Autant on sait que Google a bien ratissé le secteur par de nombreuses acquisitions telles que celle de DeepMind (UK) en 2014, autant on peut constater que nombreuses aussi sont les startups créées par d’anciens de Google et notamment des Google Labs.
- On retrouve aussi beaucoup d’anciens de l’université de Stanford et du MIT dans les startups de l’IA, généralement bardés d’un ou de plusieurs PhD en IA.
Dans ce qui va suivre, je vais indiquer la date de création des startups ainsi que les montants levés entre parenthèses lorsqu’ils sont disponibles. Même si les montants levés ne sont pas une indication suffisante de succès, elles montrent que la société a au moins attiré le regard et l’argent d’investisseurs. Les financements qui dépassent les $20m indiquent une “traction” qui peut avoir un impact mondial assez rapidement.
Deep Learning/Machine Learning
C’est la catégorie de startups la plus importante en volume mais aussi la plus déroutante car difficile à évaluer. Voici un tour d’horizon de quelques-uns de ses acteurs, notamment les plus visibles d’entre eux.
Numenta (2005, NC) est une société lancée par le créateur de Palm, Jeff Hawkins. Elle fait du deep learning en cherchant à identifier des tendances temporelles dans les données pour faire des prévisions. Leur solution Grok permet de détecter des anomalies dans des systèmes industriels et informatiques. Ils imitent le fonctionnement du cortex cérébral et de principes biologiques reprenant le principe de la mémoire par association et temporelle (Hierarchical Temporal Memory) théorisé par Jeff Hawkins en 2004 dans l’ouvrage On Intelligence, où il tente de décrire le fonctionnement du cerveau et la manière de l’émuler (PDF gratuit).

Hawkins pense que le cerveau est principalement une machine prédictive qui n’est pas forcément dotée d’une capacité de calcul parallèle intensive mais plutôt d’une mémoire associative rapidement accessible. Il insiste sur l’importance du temps dans les mécanismes de rétropropagation mise en œuvre dans les réseaux neuronaux uniquement dans les phases d’apprentissage. Alors que le cerveau bénéficie d’une mise à jour sensorielle permanente.
Les thèses de Hawkins sont intéressantes et constituaient un pot-pourri des connaissances en neurosciences il y a plus de 10 ans maintenant. Elles sont évidemment considérées comme un peu simplistes (voir ces critiques chez Jeff Kramer, Ben Goertzel et sur Quora). J’ajouterai à ces critiques que Hawkins oublie négligemment le rôle du cervelet et du cerveau limbique dans les apprentissages et le prédictif. Le cervelet contient plus de neurones que le cortex et il gère une bonne part des automatismes et mécanismes prédictifs notamment moteurs.
Numenta propose aussi NuPIC (Numenta Platform for Intelligent Computing) sous la forme d’un projet open source. Cette société est très intéressante dans le lot car elle utilise une approche technique plutôt originale qui dépasse les classiques réseaux neuronaux.
Sentient Technologies (2007, $135m, dernier tour de financement en 2014) développe pour sa part une solution d’IA massivement distribuable sur des millions de CPUs, visant les marchés de la santé, de la détection de fraudes et du du e-commerce. La société dit employer des méthodes d’IA avancées pour détecter des tendances dans les données. C’est du “big data” revisité. Le système imite les processus biologiques pour faire de l’auto-apprentissage. On trouve des morceaux de deep learning et des agents intelligents dedans. Ces agents sont évalués avec des jeux de tests et les meilleurs conservés tandis que les plus mauvais sont éliminés. Bref, c’est une sorte de Skynet. L’un des fondateurs de la société est français, Antoine Blondeau, et basé à Hong Kong.

Digital Reasoning (2000, $52m, dernière levée en 2016) a été créée par des anciens d’Oracle et de la CIA (entre autres provenances) et est financée par In-Q-Tel, le fonds d’investissement de cette dernière. Sa solution d’analyse de données est utilisée par le renseignement et la défense US ainsi que dans la finance. Comme celle de Skymind, sa solution Synthesys est en Java et ouverte. Elle permet d’analyser des données structurées et non structurées, y compris des conversations téléphoniques. Elle sert à détecter des comportements anormaux dans les communications électroniques. C’est donc un outil utilisé par la NSA dans la gestion de ses interceptions (PRISM & co).
Metamind (2014, $14m) fait de la classification automatique d’images et de textes, un peu comme ce que propose IBM Watson pour la partie texte. Elle a été créé par une équipe d’anciens de Stanford.
Scaled Inference (2014, $13,6m) propose une plateforme de machine learning en cloud via des APIs. Elle comprend de la reconnaissance de formes, des détectons d’anomalies, des algorithmes de prédiction. Startup créé par un ancien de Google. Solution pas encore disponible.
Skymind (2014, NC) a été créée par des anciens de Vicarious. Elle propose une solution open source en Java – Deeplearning4j.org – capable d’analyser des flux de données. Elle est notamment utilisée dans la détection de fraude, le commerce et le CRM.
BigMl (2011, $1,63m) a l’air d’être un outil d’analyse assez générique qui analyse les comportements clients, permet du diagnostic de matériel, dans la santé, dans les risques pour des prêts. L’ensemble s’utilise via des APIs attaquant un service en cloud. Au moins, leur site fournit des exemples de traitement de jeux de données comme ce modèle prédictif de succès de campagne de financement participatif sur Kickstarter en fonction de leurs différentes caractéristiques. Intéressant !

Cycorp (1994, NC) est une sorte de laboratoire de recherche privé en IA financé par des contrats du gouvernement US, dont la DARPA, et d’entreprises privées. Le projet de recherche Cyc dont il est issu a plus de 30 ans au compteur ! Il vise à modéliser les connaissances et à permettre d’automatiser la recherche scientifique. Il propose une suite d’outils en open source et licence commerciale permettant d’exploiter des dictionnaires, ontologies et bases de connaissances pour répondre à des questions d’analystes.
Ayadsi (2008, $98m) interprète aussi de gros volumes de données pour y identifier des signaux faibles pertinents. Le projet a démarré à Stanford et avec des financements de la DARPA et de la NSF, l’équivalent américain de l’Agence Nationale de la Recherche française.
Narrative Science (2010, $29,4m) propose Quill, une plateforme qui analyse les données structurées et non structurées issues de sources diverses pour en extraire ce qui est important et en produire des résumés automatiquement. La solution permet notamment d’exploiter les données issues de Google Analytics ou d’historique de transactions financières (ci-dessous). Startup créée par un ancien de Google et de Carnegie Mellon.

Synapsify (2012, $1,45m) a créé CORE, un outil d’analyse et de traitement en langage naturel qui fait de la recommandation de contenus.
Idibon (2012, $6,9m) analyse les textes structurés, notamment issus des réseaux sociaux, pour les classifier automatiquement et réaliser des analyses statistiques dessus.
Workfusion (2010, $36,3m) propose une solution en cloud d’orchestration et de consolidation de données pour les entreprises. Elle s’appuie sur de l’apprentissage supervisé d’outils traitant de gros volumes de données par des travailleurs crowdsourcés, dans divers métiers comme les services financiers, la comptabilité et le e-commerce. Le projet est issu de travaux de recherche du MIT.
Nutonian (2011, $4m) propose une solution d’extraction de données intelligente, capable d’identifier des tendances cachées dans les données.
Moteurs d’analyses prédictives
Les startups de ce domaine proposent des outils d’ingestion et d’analyse de gros volumes de données structurées et non structurées (documents, images, etc). Les outils d’analyse s’appuient sur un panaché de méthodes associant des statistiques, du data mining, du machine learning et du deep learning). Certains proposent leur solution en open source et la plupart les diffusent surtout en cloud.
Context Relevant (2012, $44m) propose des outils d’analyse prédictive applicables à différents marchés. Le glissement sémantique semble généralisé : au lieu de parler de big data, ce qui est trop vague, les startups parlent plutôt d’analyse prédictive qui exploite de gros volumes de données. Serait-ce de l’IA washing ? Conceptuellement oui, même si ce genre d’entreprise utilise probablement des briques de réseaux neuronaux et de machine learning en plus de méthodes plus traditionnelle.
Work Fusion ($36m) propose l’automatisation de l’exploitation de gros volumes de données non structurées. Il donne l’impression de récupérer les documents comme le fait IBM Watson dans ses outils d’ingestion. Il est par exemple capable de récupérer les résultats financiers de nombreuses entreprises et d’en présenter une synthèse. La méthode relève de la force brute au lieu d’exploiter la chimère du web sémantique qui n’a pas vraiment vu le jour. Comme le web sémantique demandait un encodage spécifique et structuré des données, peu de sites l’ont adopté et l’extraction de données reste empirique. Le traitement même de ces données pour les interroger n’a pas l’air de faire partie de leur arsenal.

Skytree (2012, $20,5m) propose une autre solution de moteur de prédiction, Skyree Infinity qui peut par exemple prédire le comportement des consommateurs et identifier des segments d’acheteurs potentiels de produits précis. La startup propose SkyTree Express en téléchargement gratuit pour analyser jusqu’à 100 millions d’éléments. Ils sont financés par la CIA via son fonds d’investissement In-Q-Tel en plus de Samsung.
Sentenai (2015, $1,8m) propose aussi une plateforme d’analyse prédictive, en cloud, qui est notamment positionnée dans l’analyse de données issues d’objets connectés. La startup, basée à Boston, a été créée par un ancien de TechStars Boston, Rohit Gupta. La startup donne l’impression de ne pas avoir grand chose d’autre dans sa besace que ses fondateurs et la capacité à recruter des développeurs sur la côte Est. Elle est très early stage et n’a pas grand chose à raconter à ce stade.
Cette catégorie comprend de nombreux autres acteurs tels que Alteryx (2010, $163m), Predixion Software (2009, $37m), RapidMiner (2007, $36m), Alpine Data Labs (2011, $23m) et Lavastorm (1999, $10m).
IA pour la recherche visuelle
L’interprétation des images est un pan entier de l’IA qui est la spécialité de nombreuses startups qui n’ont pas toutes été acquises par les GAFA ! Ces startups utilisent des techniques assez voisines basées sur le deep learning pour identifier le contenu de photos ou de vidéos pour en extraire des tags qui sont ensuite exploitées dans diverses applications.
Vicarious (2010, $72m) est spécialisé dans la reconnaissance et la classification d’images. Ils se sont fait remarquer en étant capable d’interpréter des Captcha de toutes sortes avec une efficacité de 90%.

Clarifai (2013, $72m) propose une API en cloud permettant d’accéder à leurs fonctions de reconnaissance d’images.
Cortica (2007, $38m) extrait les attributs clés d’images fixes ou animées pour les associer à des descriptifs textuels avec sa solution Image2Text. Elle est par exemple capable de reconnaitre une marque et modèle de voiture dans une vidéo ou un animal dans une photo (ci-dessous). Le tout est protégé par une centaine de brevets ! La société est originaire d’Israël.

Superfish (2006, $19,3m) développe des moteurs de recherche d’images pour les applications grand public.
Camio (2013) fournit une solution en cloud d’exploitation de vidéos de caméras de surveillance.
Deepomatic (2014, $950K) utilise le deep learning pour interpréter le contenu, la forme et la couleur d’images dans les médias et les associer à des publicités contextuelles. C’est une startup française !

Descartes Labs (2014, $8,28m) exploite via deep learning les données d’image satellite pour y découvrir comment évolue la production agricole, le cadastre des villes ou autres données géographiques.
En complément de ces startups, on trouve aussi des startups spécialisées dans le traitement du langage. Là encore, tout n’est pas chez les GAFA ou chez Nuance. On peut notamment citer DefinedCrowd (vidéo avec son ukulélé de circonstance), Weotta (2011) et MindMeld (2014).
Applications sectorielles du machine learning
L’autre plus grand groupe de startups de l’IA couvre celles qui utilisent les techniques de machine learning et deep learning, le plus souvent de nature non précisée, et qui ciblent des marchés spécifiques. Je vous les survole très rapidement, histoire de se faire une idée des applications les plus courantes.
- Dans les services financiers : avec de l’optimisation de taux d’intérêts de prêts (LendUp, qui a levé $150m), pour la détection de fraude (Sift Science, $23,6m, Riskified, $30m), pour le credit rating d’emprunteurs basée sur les réseaux sociaux (TrustingSocial) dans l’optimisation de planification financière (Anaplan, $234m, Adaptive Planning, $22,5m, Trufa, $10,9m), pour l’optimisation d’investissements (DataFox, $7,7m) et même pour identifier des startups dans lesquelles investir (Mattermark, $17,2m). Il y a aussi Vanare, Sens.ai et WealthArc.
- Dans le commerce : prédiction du trafic dans les magasins (Percolata, $5m), l’optimisation du parcours client en ligne (Gainsight, $104m, Jetlore, $7m, OnCorps, $2,3m), pour trouver la bonne taille et pour les hommes (Thread), pour optimiser l’activité de commerciaux et prévoir le comportement des clients (InsideSales, $201m !, Gainsight, $104m, Lattice, $64,7m, Clari, $26m, Wise.io, $2,61m, Spiro, $1,5m). On peut ajouter Dato (2013, $23,5m) qui propose un système de recommandation dans le ecommerce basé sur du machine learning. La startup a été montée par des anciens de Carnegie Mellon sous la forme initiale d’un projet open source.
- Dans le marketing, pour l’optimisation des messages et contenus (Captora, $27m, Persado, $36m), pour la gestion ou l’analyse des données issues des médias sociaux (Meshfire, $350K, Cortex, $500K, SimpleReach, $10,6m).
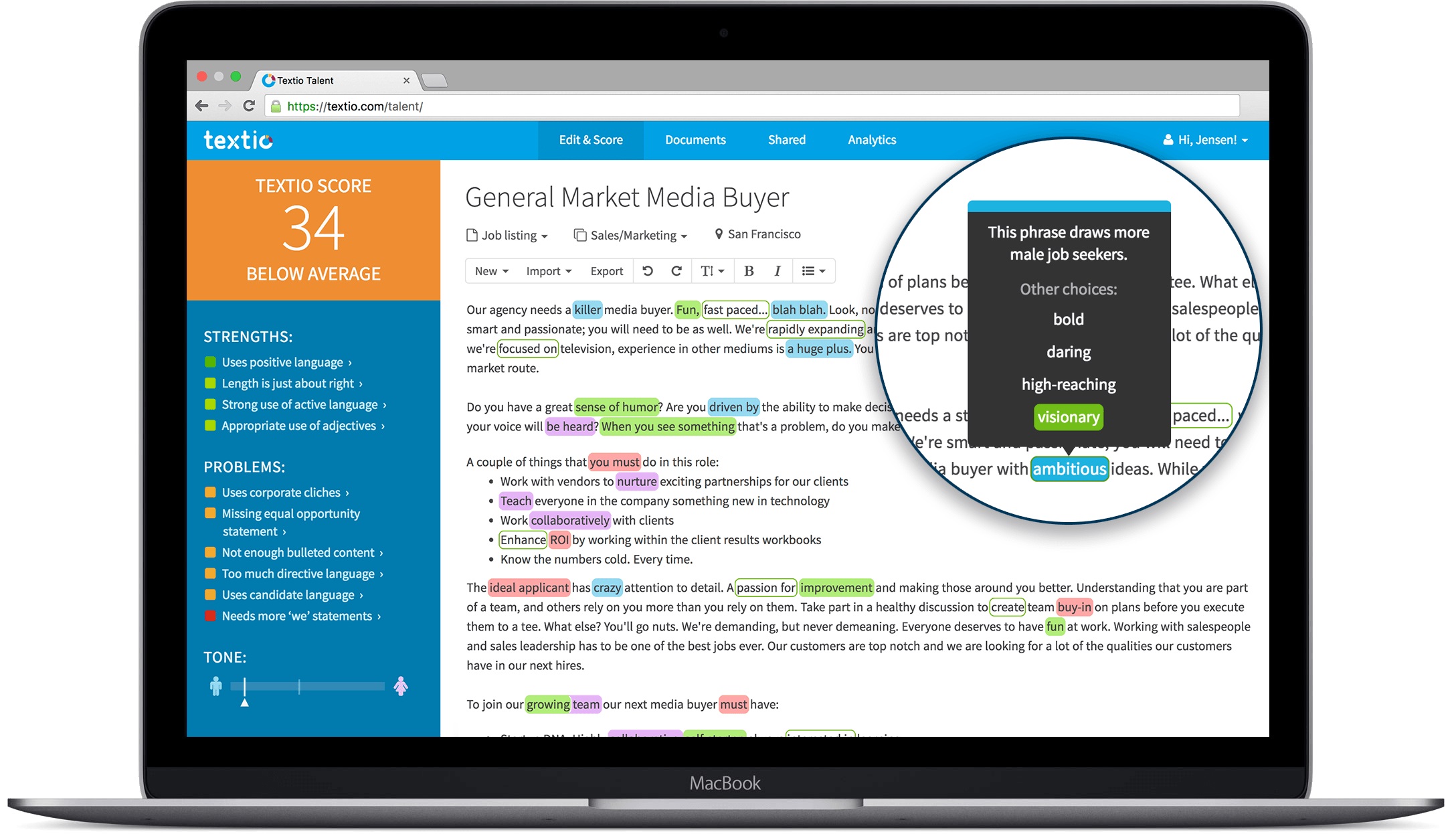
- Dans les ressources humaines avec de l’analyse prédictive pour identifier des talents à chasser (Entelo, $8,7m, Gild, $26mn). Il y a aussi Textio qui aide à rédiger des annonces d’emploi efficaces et analyse les réponses des candidats (exemple ci-dessous).
- Dans les services juridiques avec divers systèmes d’interrogation de bases de connaissances (Casetext, $8,8m, Judicata, $7,8m, et Ross Intelligence, qui s’appuie sur IBM Watson). Il y a aussi Kira et Legal Robot.
- Dans les universités pour les aider à recruter les meilleurs étudiants (Plexuss) ou, au contraire, pour aider ces derniers à trouver la meilleure université (Admitster).
- Dans la recherche scientifique : pour gérer une communauté mondiale de data scientists (Kaggle, $12,75m), pour découvrir des étoiles selon leurs caractéristiques ().
- Dans la sécurité informatique pour détecter les tentatives de phishing (GreatHorn, $2,6m) ou avec Lookout (2007, $282m) qui sécurise les mobiles avec un modèle prédictif.
- Dans l’agriculture pour robotiser la culture et personnaliser le soin de chaque plan (Blue River Technology, $30,35m). La société propose un système robotisé de culture de laitues contenant une bardée de capteurs, dont certains sont 3D, pour optimiser l’entretien de laitues ou de plants de mais (ci-dessous).

- Dans les contenus avec le canadien Landr ($10,4m) un service en cloud pour automatiser le mixage audio et créer des morceaux de musique agréables à l’écoute. Il y a aussi Narrative Science (2010, $29,4m) qui est capable de rédiger tout seul des textes à partir de données structurées et non structurées, utilisé notamment dans les médias et le marketing.
Applications dans la santé
C’est le marché vertical le plus attirant pour les startups de l’IA avec celui de la finance et du commerce. L’IA est notamment utilisée dans la génomique et dans l’aide au diagnostic dans la lignée de la solution en oncologie que nous avons vue au sujet d’IBM Watson dans l’article précédent.
Deep Genomics (2014, $3,7m) a créé le DG Engine qui analyse les variations du génome – les mutations de l’ADN – et la manière dont elles affectent le fonctionnement des cellules et génèrent des pathologies. On appelle cela les “genome-wide association study” (GWAS) qui font des analyses de corrélations entre modifications des gênes et pathologies (le “phénotype”). Les analyses réalisées par Deep Genomics ont la particularité d’intégrer tout le cycle de vie des gênes et notamment leur épissage – qui correspond à l’extraction de la partie codante des gênes – jusqu’à leur translation, à savoir la conversion de l’ARN qui résulte de l’épissage en protéines dans les ribosomes. Ils proposent en open source leur base de données SPIDEX de mutations de gênes et de leurs effets sur leur épissage. Voir The human splicing code reveals new insights into the genetic determinants of disease qui explique les fondements scientifiques de leur procédé. L’ambition est de mener à de la médecine personnalisée mais on en est encore loin. La société a été cofondée par Brendan Frey, qui avait fait son PhD à Toronton avec Geoff Hinton, un chercheur canadien à l’origine du renouveau dans les réseaux neuronaux au milieu des années 2000 et qui est maintenant chez Google.
Enlitic (2014, $15m) propose de l’aide au diagnostic en s’appuyant principalement sur résultats de systèmes d’imagerie médical (IRM, scanner, radios) et sur du deep learning. C’est une sorte d’équivalent apparemment généraliste d’IBM Watson qui se positionne plutôt dans la prévention, détectant des pathologies émergentes le plus tôt possible, notamment les cancers du poumon. Il aide aussi à identifier plusieurs pathologies simultanément. Cf la vidéo de son CEO, Jeremy Howard à TEDx Bruxelles en décembre 2014. Il y aborde un point clé : il n’y a pas assez de médecins dans le monde. L’automatisation des diagnostics est donc un impératif incontournable.

Ginger.io (2011, $28,2m) a créé un outil de diagnostic et de prescription de traitement pour diverses pathologies neuropsychologiques. Il exploite des applications mobiles pour le diagnostic et du machine learning. La solution permet un auto-traitement de certaines pathologies par les patients.
Lumiata (2013, $10m) est dans la même lignée un système d’analyse de situation de patient permettant d’accélérer les diagnostics, notamment en milieu hospitalier.
MedWhat (2010, $560K) propose une solution générique d’aide au diagnostic qui s’appuie sur la panoplie totale de l’IA (deep learning, machine learning, NLP). Elle se matérialise sous la forme d’une application mobile faisant tourner un agent conversationnel à qui ont indique ses symptômes, qui pose des questions de qualification et oriente ensuite le patient (vidéo de démo). Elle stocke aussi le dossier médical du patient. La startup a été créée par des anciens de Stanford, mais cela ne semble pas suffisant pour décoller !
Behold.ai (2015, $20K) a développé une solution d’analyse d’imagerie médicale pour aide les radiologues à faire leur diagnostic. Cela s’appuie sur du machine learning. Le système compare les images de radiologie avec et sans pathologies pour détecter les zones à problèmes, comme les nodules et autres formes de lésions.
Cognitive Scale (2013) a créé la solution Cognitive Clouds. Elle est notamment proposée aux adolescents atteints de diabète type 1 pour les aider à se réguler, en intégrant les aspects médicaux (prise d’insuline, suivi de glycémie), d’activité physique et d’alimentation. Il y a des dizaines de startups qui visent le même marché et avec plus ou moins de bonheur. Très souvent, elles méconnaissent le fonctionnement des diabétiques dans la régulation de leur vie et leur segmentation.
atomwise (2012, $6,35m) utilise le machine learning pour découvrir de nouveaux médicaments et vérifier leur non toxicité. Le principe consiste à simuler l’interaction entre des milliers de médicaments connus et une pathologie telle qu’un virus, et d’identifier celles qui pourraient avoir un effet par simulation des interactions moléculaires. Un premier résultat aurait été obtenu en 2015 sur un virus d’Ebola. La simulation in-silico permet de choisir quelques médicaments qui sont ensuite testés in-vitro avec des cellules humaines.
MedAware (2012, $1m) fournit une solution qui permet d’éviter les erreurs de prescription médicamenteuse en temps réel pour les médecins. Avec des morceaux de big data et de machine learning dedans qui exploite notamment des bases de données médicales d’historiques de patients.
Hindsait (2013) propose une solution en cloud servant à identifier les déviations dans les dépenses de santé. Cela sert donc surtout aux financeurs des systèmes de santé que sont les assurances publiques, privées et les mutuelles. Ca fait moins rêver le patient !
___________________________________
C’en est terminé pour ce petit catalogue à la Prévert de startups de l’IA. Il est certainement incomplet et je pourrais en ajouter au fil de l’eau.
Dans la partie suivante, je fais un tour de startups non citées ci-dessous car elles ont été acquises par de grand’es entreprises du secteur et notamment par les GAFA ainsi que par IBM ou Microsoft. Cela aliment d’ailleurs quelques fantasmes sur leurs avancées dans l’IA, notamment focalisés sur Google qui aurait selon les commentateurs acquis tout ce qui existait de bien autour de l’IA. C’est une vue de l’esprit car la compétence sur l’IA est très distribuée dans le monde, aussi bien dans les laboratoires de recherche que dans les startups.
____________________________________
Vous pouvez consulter tous les épisodes de ce roman fleuve de printemps sur l’intelligence artificielle :
Episode 1 : sémantique et questions clés
Episode 2 : histoire et technologies de l’intelligence artificielle
Episode 3 : IBM Watson et le marketing de l’intelligence artificielle
Episode 4 : les startups US de l’intelligence artificielle
Episode 5 : les startups acquises par les grands du numérique
Episode 6 : les startups françaises de l’intelligence artificielle
Episode 7 : la modélisation et la copie du cerveau
Episode 8 : évolutions de la loi de Moore et applications à l’intelligence artificielle
Episode 9 : la robotisation en marche des métiers
![]()
![]()
![]()

Reçevez par email les alertes de parution de nouveaux articles :
![]()
![]()
![]()



























 Articles
Articles
Je vous recommande la lecture du Post de Olivier Ezratty.
Merci Olivier pour ces communications ! https://t.co/lv9NpC6yAc
Un grand merci M. Ezratty pour ces articles de fonds.
A lire pepouz au coin du feu ou sur le trône “Les avancées de l’intelligence artificielle – 4” de @olivez sur https://t.co/xdbcRZg2se
Si vous voulez comprendre un peu plus les startups du domaine de l’intelligence Artificielle et comment elles vont i…https://t.co/XZ1palnSZF
Article éclairé et éclairant de @olivez sur l’#IA: un must . “Les avancées de l’intelligence artificielle – 4” sur https://t.co/6sM60ALl8l
Très belle série, très bel article qui permet une plongée dans l’univers protéiforme de l’iA. A mentionner dans les petits français qui montent ( et ex distingués du MIT eux aussi) Snips, et son fondateur Rand Hindi. ITW sur Influencia http://www.influencia.net/larevue/vivre-connecte/index.php?page=14
Merci du feedback.
J’ai bien prévu de parler de Snips dans la sixième partie, dédiée aux startups françaises !
D’autres français à ne pas oublier ?
Un grand merci @Olivez “Les avancées de l’intelligence artificielle – 4” de @olivez sur https://t.co/wFlX8a87Zy
J’avais loupé cet excellent article “Les avancées de l’intelligence artificielle – 4” de @olivez https://t.co/xuH988O4XA #IA #innovation