
Après avoir décrit l’objet du logiciel Outwit Hub, passons à un petit tutorial qui vous permettra de l’expérimenter pour une application pratique: la récupération de listes de sites web. Il vous faudra d’abord installer ou disposer de Firefox 3.x de Firefox. Ensuite, vous installerez la bêta d’Outwit Hub. Elle fonctionne sur Windows, MacOS comme sur Linux.
Je vais utiliser ici un exemple de récupération de données structurées déjà exploité pour la préparation de mes supports de cours sur l’économie de l’innovation : la liste du Forbes 2000 qui regroupe les 2000 plus grandes entreprises mondiales. Elle est porteuse d’une très grande richesse d’informations. Cette liste apparait sous forme de tableaux que l’on peut copier coller à la main dans Excel. Mais il faut charger 20 pages ce qui est bien fastidieux.
Alors, lançons Firefox puis Outwit Hub à partir de l’icone installée dans la toolbar de Firefox par ce dernier comme indiqué ci-dessous.

Dans la barre d’URL d’Outwit Hub, collez l’URL de Forbes. Faites “Enter” et la page s’affiche comme dans tout navigateur. Ensuite, cliquez sur le tab “Data” comme indiqué ci-dessous.
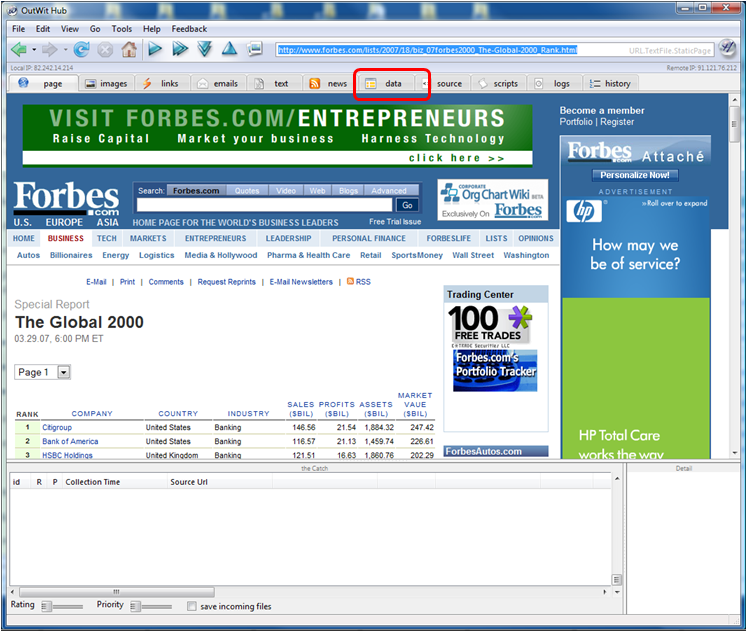
Cela affiche les données tabulées de la page HTML. Mais on n’a pas encore un beau tableau. Pour ce faire, cliquez sur le bouton “Guess” comme indiqué ci-dessous. Cette fonction déclenche la détection automatique d’un véritable tableau de données structurées par Outwit.
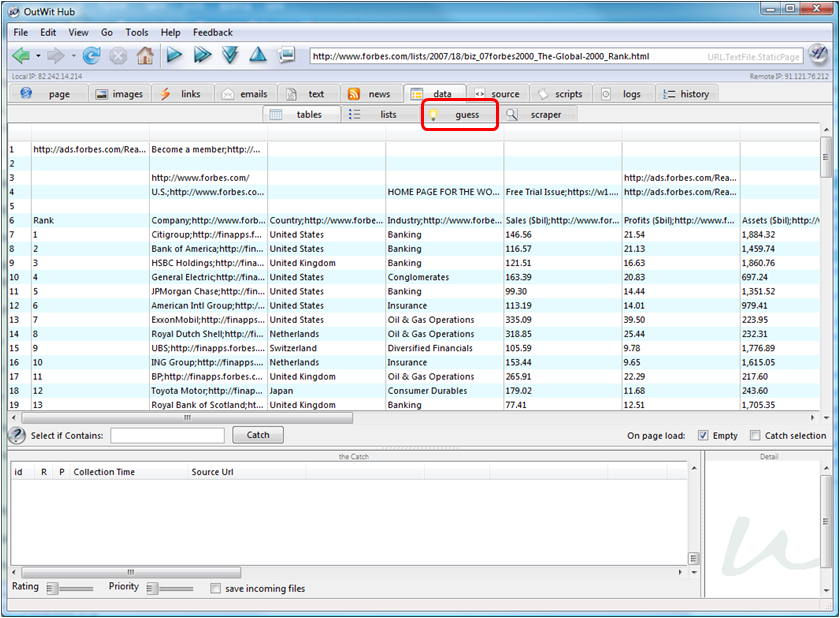
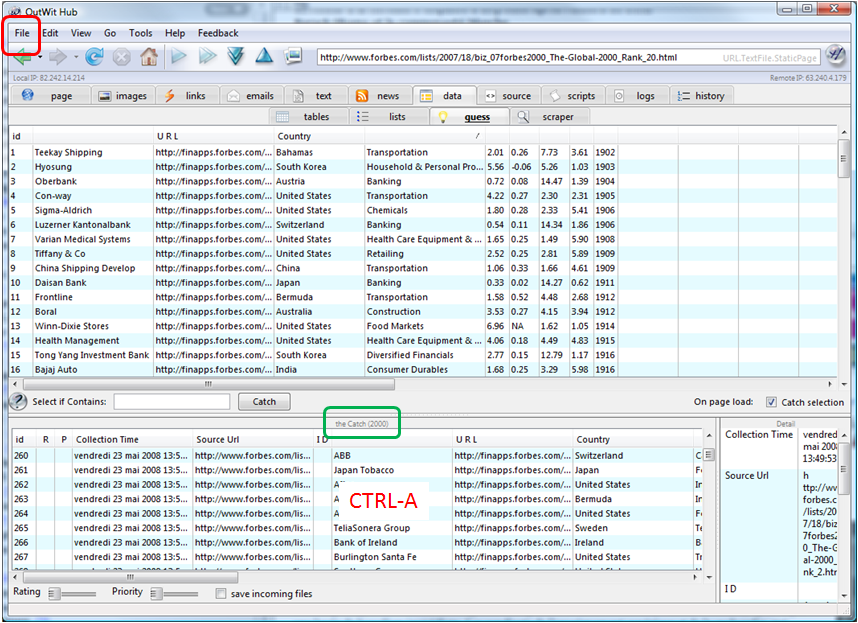
Le résultat apparait ci-dessous. A partir de là, on va sélectionner toutes les lignes dans la liste, par exemple en cliquant sur une ligne et en faisant “CTRL-A” avec le clavier. Et puis, on va la copier dans la zone en bas de la fenêtre qui est le “Catch” en cliquant sur le bouton du même nom. Le catch, c’est ce que l’on a attrapé dans les pages et qui s’accumule au fur et à mesure. Ensuite, on peut récupérer ce qu’il y a dans le catch de différentes manières selon qu’il s’agit d’images ou de listes.
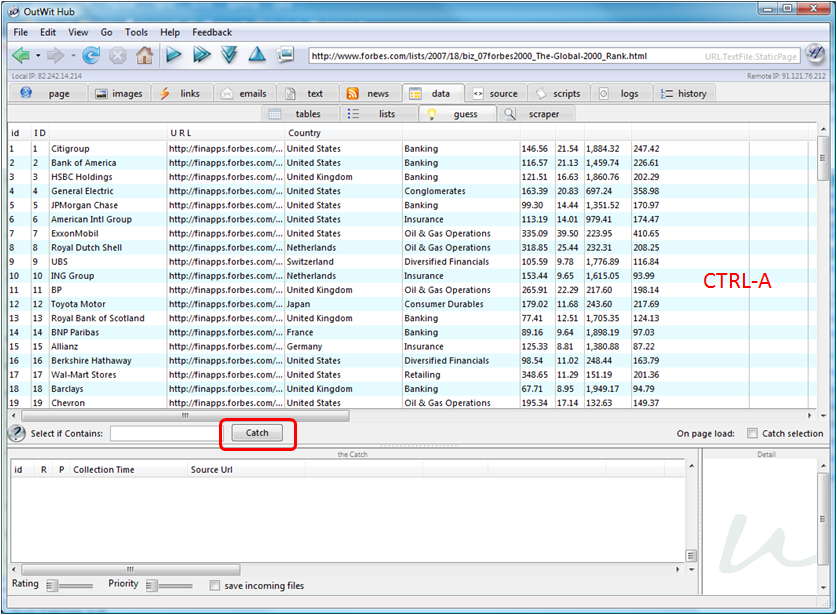
Maintenant, nous allons lancer le processus qui va automatiquement récupérer la suite du Forbes 2000 dans les 19 pages web suivantes. Il faut d’abord sélectionner la checkbox “Catch selection” qui indique que dans toute ouverture de page ou sélection de page suivante, le contenu identifié sera automatiquement basculé dans le catch. Ensuite, on cliquera sur la “double flèche droite” (fast forward) qui est dans la barre d’outils en haut de Outwit. Elle déclenchera l’analyse automatique des pages suivantes jusqu’à la vingtième. Si on veut le faire à la main, on peut utiliser le bouton “flèche droite” (“Play”) page par page. On peut aussi arrêter le scan automatique des pages avec ESC ou en cliquant à nouveau sur la double flèche.
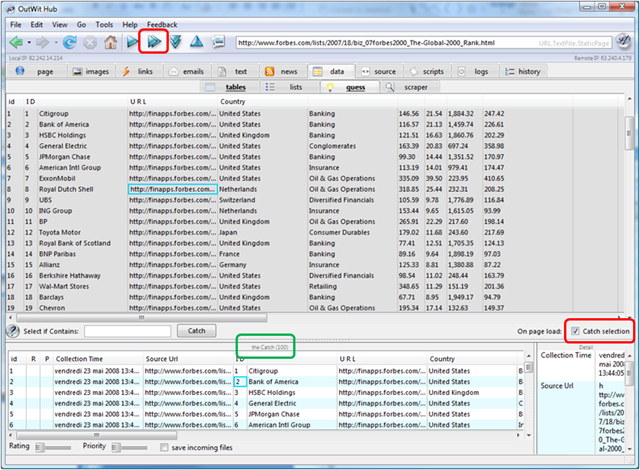
Une fois les 20 pages scannées ce qui prend quelques minutes à peine, le catch comprend bien 2000 entrées. On va maintenant le sauvegarder pour l’exploiter.
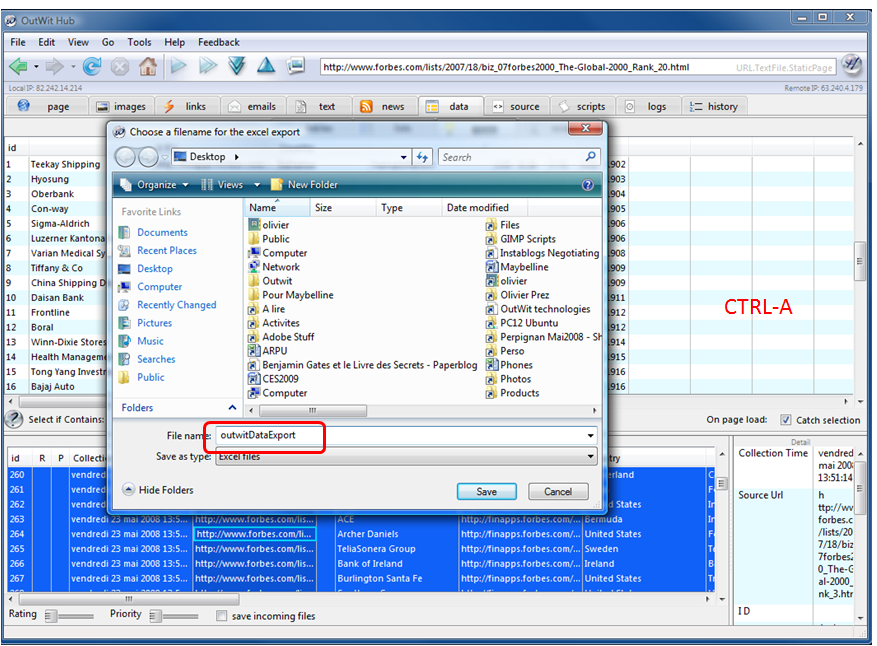
Pour ce faire, on va dans le menu “File” et on lance “Export selection as…“. Le seul format supporté est pour l’instant Excel. C’est en fait un schéma XML supporté par Excel, mais je ne sais pas trop lequel. Et il n’est pas lisible dans OpenOffice 2.4. Un export CSV est en tout cas prévu à terme. Et on peut tout de même copier la sélection du haut ou celle du catch dans le presse papier pour la récupérer ailleurs (avec le bouton droit de la souris et “Copy“).
Et on ouvre le fichier sous Excel, version 2007 US dans l’exemple ci-dessous (ça fonctionne peut-être sous OpenOffice). On élimine ensuite les colonnes inutiles. On peut constater que la colonne “Rank” n’a pas été bien récupérée mais ce n’est pas grave dans ce cas là. C’est un défaut qui sera traité dans les évolutions d’Outwit pour faire en sorte que la détection automatique de la structure des tables d’une page ne soit pas refaire à chaque page.
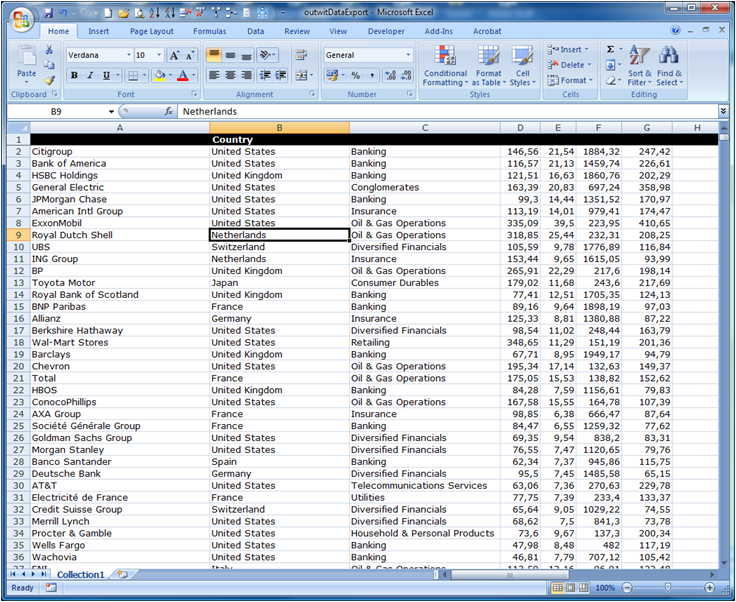
Pour exploiter les données, il faut les normaliser au format français : on sélectionne les colonnes de chiffres, on utilise la fonction de Recherche/Remplacement d’Excel pour remplacer les “,” (virgules) par rien du tout, et ensuite les “.” par “,” et le tour est joué. Là encore, cette transformation devrait être effectuée automatiquement par Outwit Hub après la fin de la bêta en fonction de vos “Regional Settings”.
Et hop, on créé un petit tableau dynamique croisé et un camember avec par exemple la répartition par pays de la capitalisation boursière des 2000 plus grandes entreprises mondiales.

Pour l’instant, ce processus automatique (Guess) ne fonctionne pas encore parfaitement sur tous les sites. J’ai pu le tester avec succès sur Kelkoo.fr et quelques autres sites comme des sites de recherche d’emploi. Mais entre les quatre fonctionnalités d’extraction de données sous l’onglet “Data” (trois sont automatiques: tables, listes et guess, et une est manuelle : scrapers), il y a en général toujours un moyen de s’en sortir. D’autres tutoriaux suivront qui seront publiés sur le site d’Outwit.
A vous de jouer maintenant…
Le tutoriel suivant traitera de la récupération d’images.
Article mis à jour le 1ier août 2008 pour tenir compte de la compatibilité d’Outwit Hub avec Firefox. Mais le tutoriel n’a pas été encore retesté dans cette version.
![]()
![]()
![]()

Reçevez par email les alertes de parution de nouveaux articles :
![]()
![]()
![]()



























 Articles
Articles
ma-gni-fi-que !
Merci !
Vraiment trippant.. Merci pour la découverte je ne connaissais pas du tout Outwit.
Bonsoir,
Je viens de découvrir Outwit.
Je m’intéresse justement à la récupérations de listes à partir de sites boursiers.
Votre test tombe à pic. Il met en appétit !
Etonnant que cet outil semble rester confidentiel.
Merci pour l’information
flying.fish